A deep dive into Bravado’s scraper protection solution development process
By Aleksey Shaykhaleev, Nancy Zhu
Scraper Alert
In October 2020, a massive influx of users registered on Bravado in a span of 3 minutes. More waves of new user registrations occurred in 3-minute intervals every hour in the following hours like clockwork. While getting new users is a cause for celebration, the suspiciously regular pattern of signups amid the absence of major product changes alerted the Bravado developer team.
After investigating, we found out the culprit was an overseas company who was scraping information from the Bravado website. For context, our website houses tens of thousands of salespeople’s public user profiles containing unique information, such as deal data and customer testimonials (here’s an example).
At the time, Bravado had scraper protection mechanisms that automatically throttle IP addresses sending too many requests on the same URL within a short amount of time (e.g. 50 requests in 1 hour). However, this scraper bypassed the protection by continuously adding new servers with hundreds of IP addresses from different locations. They also disguised themselves as search engines by putting strings such as “Googlebot” or “Facebot” in the user agent. The scraper attack posed two problems Bravado needed to solve:
- Scalably block suspicious IP addresses. The scraper was aggressively increasing the number of requests they sent, even causing a distributed denial-of-service (DDoS) attack that brought down the Bravado website at one point. We needed an efficient way to identify and block malicious bots.
- Reliably identify malicious bots from search engine crawlers and real users. For SEO purposes, we don’t block search engine crawlers such as Googlebot from crawling Bravado public information. It was imperative we catch suspicious IP addresses that pretend to be those crawlers by identifying behavior patterns and block them quickly.
Solution Implementation
Solution Brainstorming
We decided to kill two birds with one stone — setting a challenging, real-world task for backend engineering candidates, while also finding a solution to our scraper woes. Our VP of Engineering, Anton, assigned this task to Aleksey, an experienced Ruby developer who was interviewing with Bravado at the time. We gave Aleksey the context, feature requirements, and a fair market hourly rate; we also invited him to a planning call with the entire engineering team for solution brainstorming.
The team considered several solutions implemented by other companies, including paid services hosted on AWS that use AI/ML for malicious bot detection.
Solution Overview
Considering our needs, budget, and the scale of attacks, the team decided to implement reverse DNS and a user-friendly dashboard for triaging suspicious IP addresses.
The Domain Name System (DNS) is queried in a forward DNS lookup to translate human-readable names into IP addresses. A reverse DNS lookup accomplishes the opposite by translating an IP address to the domain name associated. For example, we received a request from an IP address whose user agent included “Googlebot”; we found out with a reverse DNS lookup that the domain belonged to a small provider in Russia instead of Google, enabling us to permanently block the IP address.
To implement reverse DNS, the developers found open-source code from Github that provided curated rules for checking bot requests for various search engines. We also forked the code by adding support for additional search engines such as Petalbot that were blocked by our rules. Then we wrote the code for Bravado on Ruby on Rails.
To streamline the monitor and response process, the developers created a #attack-alerts Slack channel for real-time alerts about suspicious IP addresses.
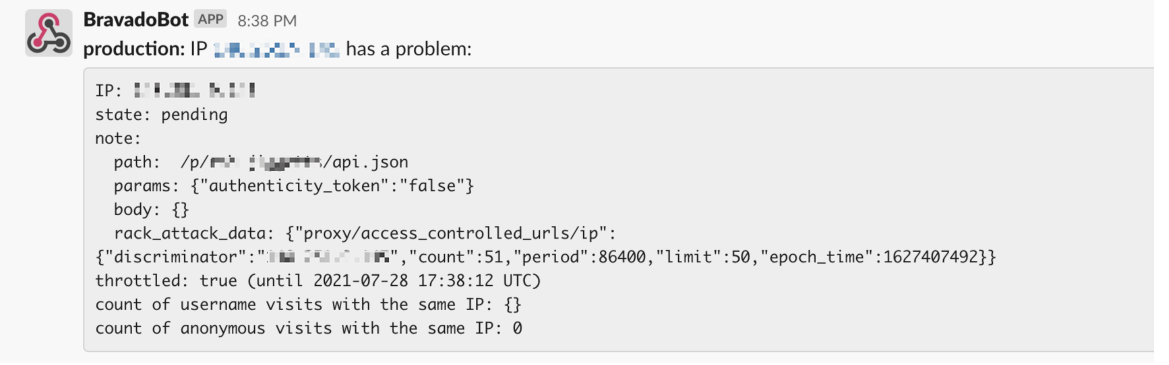
To save developers time on checking and blocking IP addresses, the team also built a dashboard to easily complete the actions.

After successfully implementing the solutions and experiencing the engineering culture first-hand, Aleksey officially joined Bravado (and then coauthored this blog post!).
Unforeseen issues
Since its implementation, our scraper protection solution has protected the Bravado user profiles, feed, and post pages from 320+ malicious bots. But new problems arose.
In April this year, our developers discovered we had accidentally banned hundreds of real users. Initial investigation showed that reverse DNS was working and the scraper-protection system was intact. As the team dug deeper into the problem, suspicion arose when we noticed the user agents for these IP addresses all contain “Twitterbot” like the following:
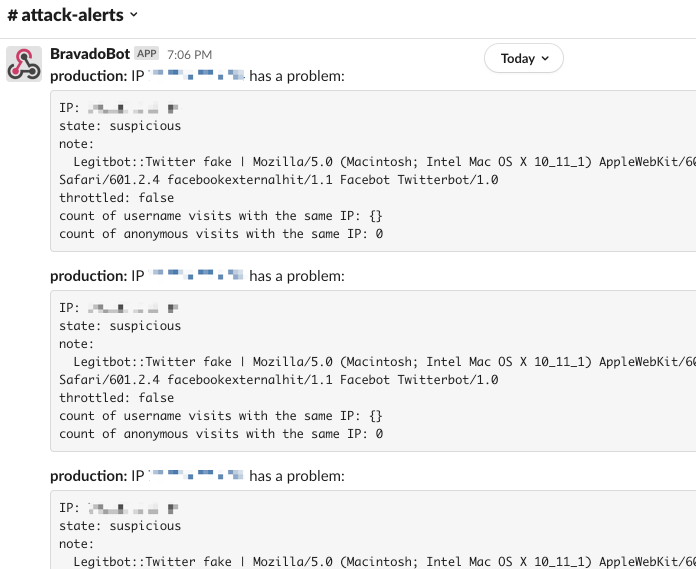
Through research, we discovered that Apple’s iMessage impersonates Twitter and Facebook bots when scraping websites for Open Graph images (you can read more about it in this article). When a Bravado user shares a Bravado URL (of a post or user profile) via iMessage, iMessage makes a request for the URL using a user agent like the following:

In our case, iMessage developers pretended to be Twitter to crawl the most optimized and accurate Open Graph image for a URL, possibly among other reasons. Since these IP addresses returned non-Twitter domains through reverse DNS lookups, they were blocked by Bravado under our strict scraper protection rules.
However, to prevent our system from blocking real Bravado users, we improved the alert messages in the #attack-alerts Slack channel by tracking the count of visits from the same IP message; adjusted our rules to block suspicious IP addresses with a high count of visits; and refactored our code to accommodate the new requirements.
Epilogue
As Bravado experiences exponential growth in users and proprietary user data, our team has continued to improve our scraper protection solutions. We’ve also begun to explore other fraud-protection solutions to add to our tech stack. No matter what new challenges come our way, we are prepared to tackle them head-on and protect our user data from malicious attacks.
Bravado is hiring! To view and apply to open roles, visit our Careers page.
