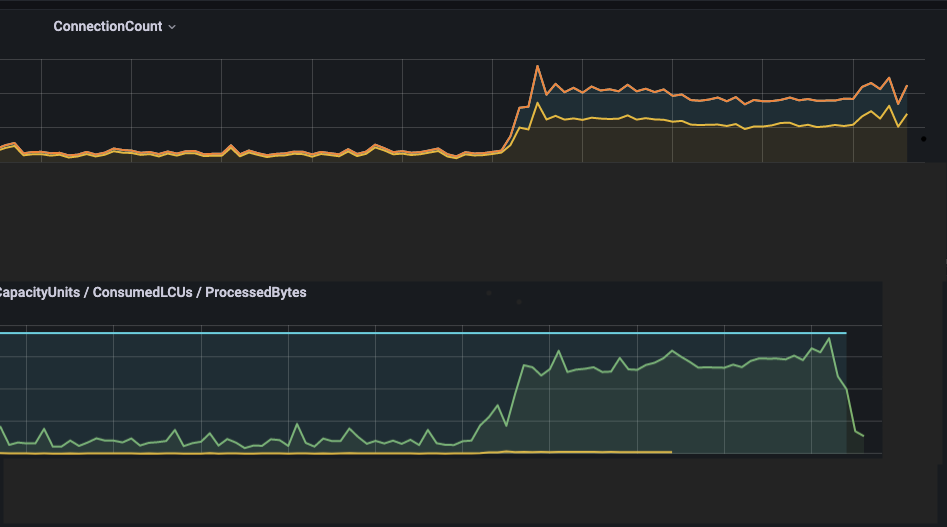
On February 4, 2022, we had an incident on our web application. There was a huge spike in traffic and I got an alert from our monitoring system about a couple of requests returning 502 errors. Most of these requests were to our frontend containers. During this incident, the frequency of requests, which were usually at about 40 requests per minute, increased by as much as 7 times more.
The wrong way
I had some experience with DDoS attacks, and this scenario seemed very much like one. I notified the rest of the team, and together we began to investigate the situation. In the meantime, I increased the number of replicas in our Kubernetes cluster and also increased the number of frontend and backend pods. This gave more capacity to our containers to handle the heavy load of requests, and we were able to reduce the number of failing requests by a healthy margin. However, the situation persisted from time to time and requests continued to fail.
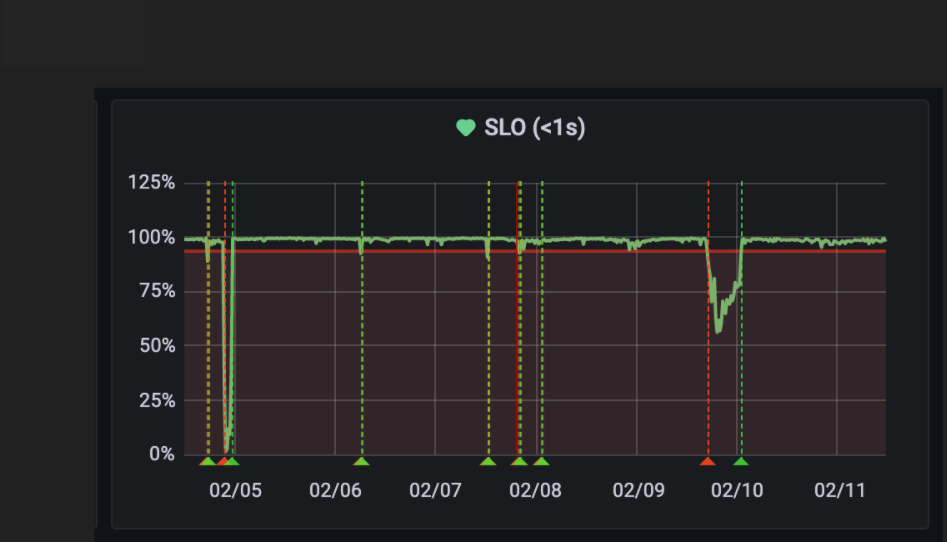
About four hours after the incident started, the errors stopped completely and the application was back to normal. The way the errors stopped, abruptly, without any solution, further confirmed my suspicions that this was a DDoS attack.
What is a DDoS attack?
A Distributed Denial-of-Service (DDoS) attack is a malicious attempt to disrupt the normal traffic of a targeted server, service, or network by overwhelming the target or its surrounding infrastructure with a flood of Internet traffic.
Following my suspicion, I had a discussion with our VP of engineering, Anton Pleshivtsev, on how we could protect the application from such attacks. We decided to try out two solutions:
- Cloudflare: Cloudflare secures and ensures the reliability of your external-facing resources such as websites, APIs, and applications. It protects your internal resources such as behind-the-firewall applications.
- AWS WAF: AWS WAF is a web application firewall that helps protect your web applications or APIs against common web exploits and bots that may affect availability.
I proposed to try these two solutions on the application. I set up an account on Cloudflare and, as a requirement, moved our DNS zone servers to Cloudflare. Furthermore, I also implemented a firewall application with AWS WAF. After they were both set up, I shared these solutions with the rest of the team, and we agreed that Cloudflare was a lot more sophisticated and best suited for the kind of solution we needed.
However, on February 9, 2022, we had another similar incident. Traffic spiked, requests were failing sporadically once again.
When the first incident occurred, I had noticed that there was a huge load on the database instance serving the application in production. I decided this was pretty normal and merely a result of the huge spike in the number of requests. However, upon seeing the incident again, one of our Backend Engineers, Otavio, suggested that we take a closer look at the database.
We launched a parallel investigation on the database and our Cloudflare solution respectively. Everything seemed okay with our Cloudflare solution, but we had some interesting findings upon taking a closer look at the database. We found that there were specific requests to the database that took a long time to get resolved. Tracing the request, we found the source to be from our Data Science team.
Bravado’s database setup includes a primary database, called the master instance, and an asynchronous replica, called the read-replica instance. The read-replica instance is available to our Data Science team for their applications/services, while the master instance primarily serves the application in production. However, this one application called Louis, belonging to the Data Science team, was pointing to the master instance of the database. Louis made some queries with join requests to a large table in the database, and this turned out to be quite expensive. Not only were these very expensive requests, but there were also a lot of them, and they took a long time before getting resolved. These queries caused a heavy load on the database and blocked other requests coming from our backend application.
Our frontend containers are configured to run regular health checks on our backend. If this health check fails, the frontend containers would restart. When requests from the backend could not be resolved, they returned errors, causing the health checks to fail and as multiple health checks failed, our frontend containers restarted multiple times. This is why requests to our frontend containers were failing.
Finding the real source
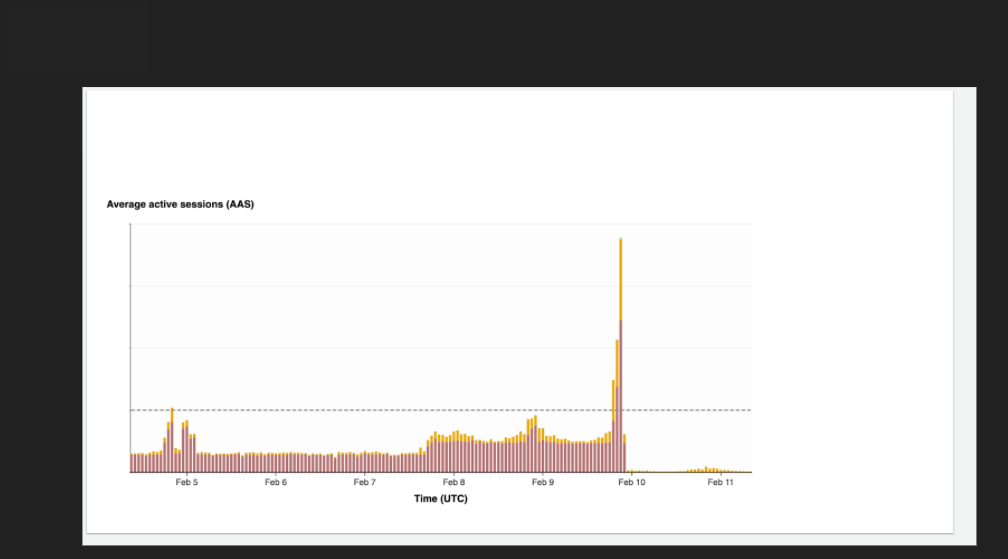
The source of the problem we found when we built the DB load diagram divided by users, which clearly showed huge load coming from the Data Science team.
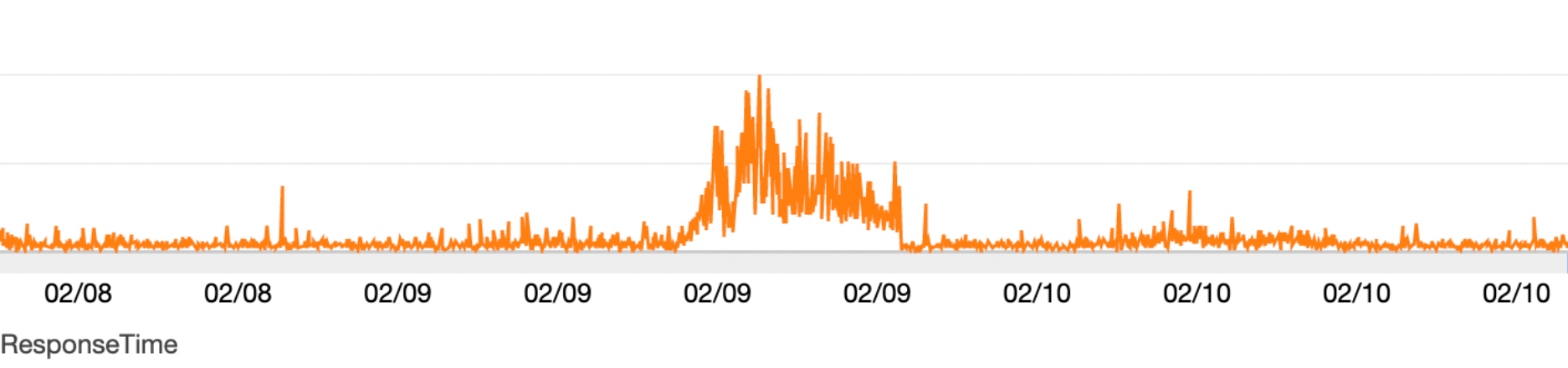
I quickly created a separate replica instance and reached out to the Data Science team and requested that they disconnect Louis from the master instance and point to this instance instead. Immediately, the huge spike in requests dropped, our frontend containers were now stable, and the problem was resolved.
We can also see a huge drop in ReadIOPS after the solution.

As a result, the average response times got back to normal.
We then advised the Data Science team to connect to the read-replica instance instead of Master for heavy requests coming from this service from using the master instance.
Conclusion
It was easy to assume this was a DDoS attack because of the huge spike in traffic and requests coming from a lot of IPs. However, modular systems can be very complex, the problem came from an unexpected unsuspecting source making heavy requests and this triggered a trail of side effects, ultimately causing our frontend containers to restart a couple of times. We needed to dive deeper by taking a closer look at our internal services, drilling the problem down to the database, figuring out what instance was affected and from which particular user in the database this was triggered. Our DS application - Louis, directly connected to the master database instance instead of requesting data from the replica and executed the expensive queries which made it more difficult to figure out the root cause since we couldn't see any traces in our APM solution. Working as a winning team, we were able to figure this out together and resolved the issue.
This incident also led us to visit the protective measure we put in place against DDoS attacks. While this was not a DDoS attack, we’re a growing company, and might experience such attacks in the future, and should be cautious. While we regret that this incident may have impacted our user’s experience on our application, we are grateful for the opportunity to make our systems more secure.